
About me
I'm a Postdoctoral Scholar in Computer Science at Stanford University, advised by Dan Jurafsky. I develop robust neural methods for speech and language processing that span from creating comprehensive benchmarks for evaluating model performance to building open-source systems that work across diverse linguistic contexts. My research focuses on both the technical challenges of improving model capabilities and the equity challenges of extending these advances to speakers of underrepresented languages and communities worldwide. I was awarded my PhD with the highest distinction (cum laude) at the University of Groningen, where I was advised by Martijn Wieling and Mark Liberman. I have also been a visiting researcher at Delft University of Technology, the Stanford NLP group, and the University of Pennsylvania. My current position is supported by an NWO Rubicon fellowship.
Updates:
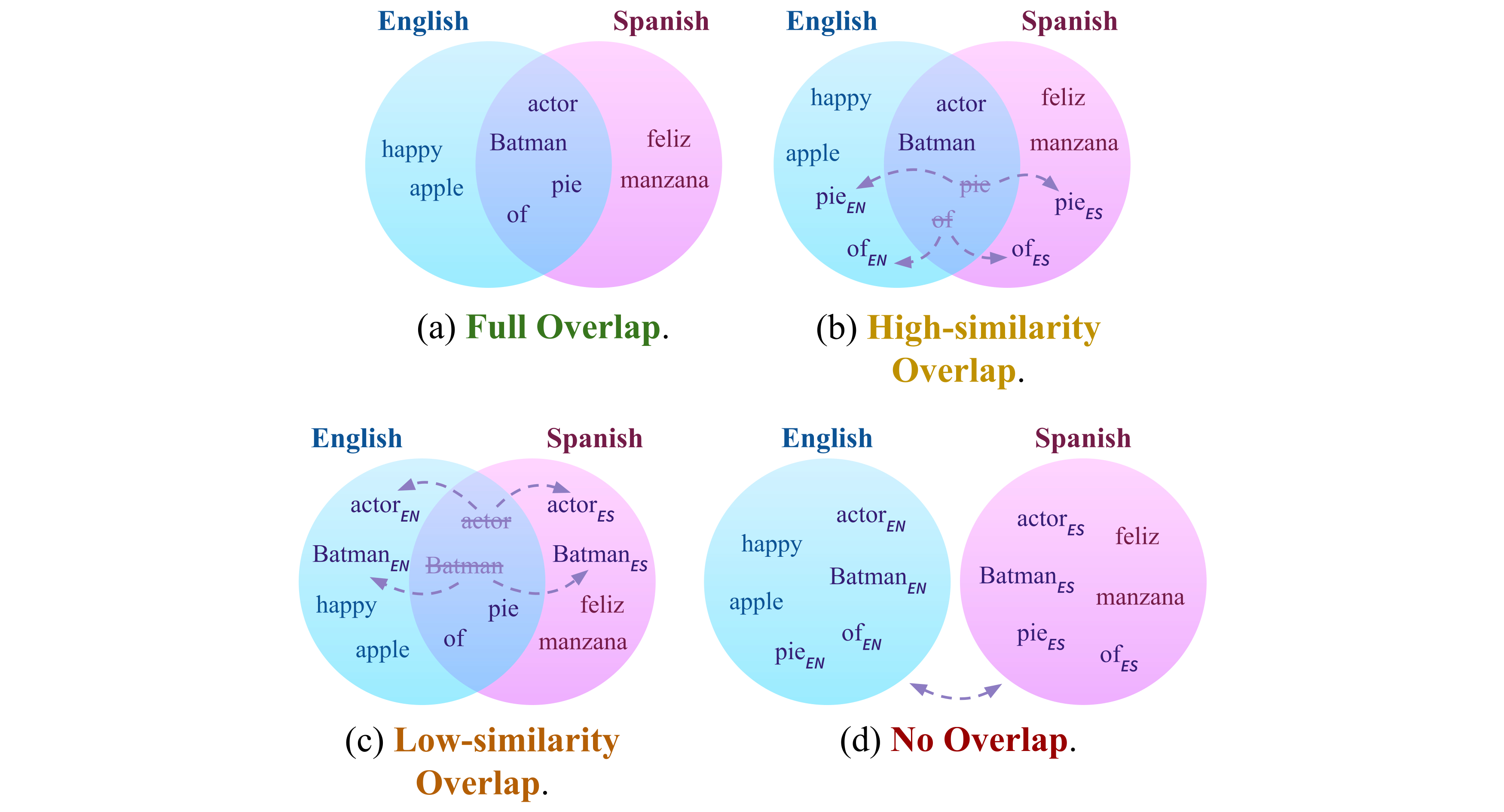
- Read about False Friends Are Not Foes: Investigating Vocabulary Overlap in Multilingual Language Models, which systematically investigates how subword vocabulary overlap affects cross-lingual transfer in bilingual language models.
- Read about OLMoASR, which is our new series of open English speech recognition models.
- My PhD thesis was nominated for the University of Groningen's best thesis of 2023.
E-mail: bartelds@stanford.edu
Google Scholar | Github | X | Bluesky | LinkedIn
Highlighted Publications
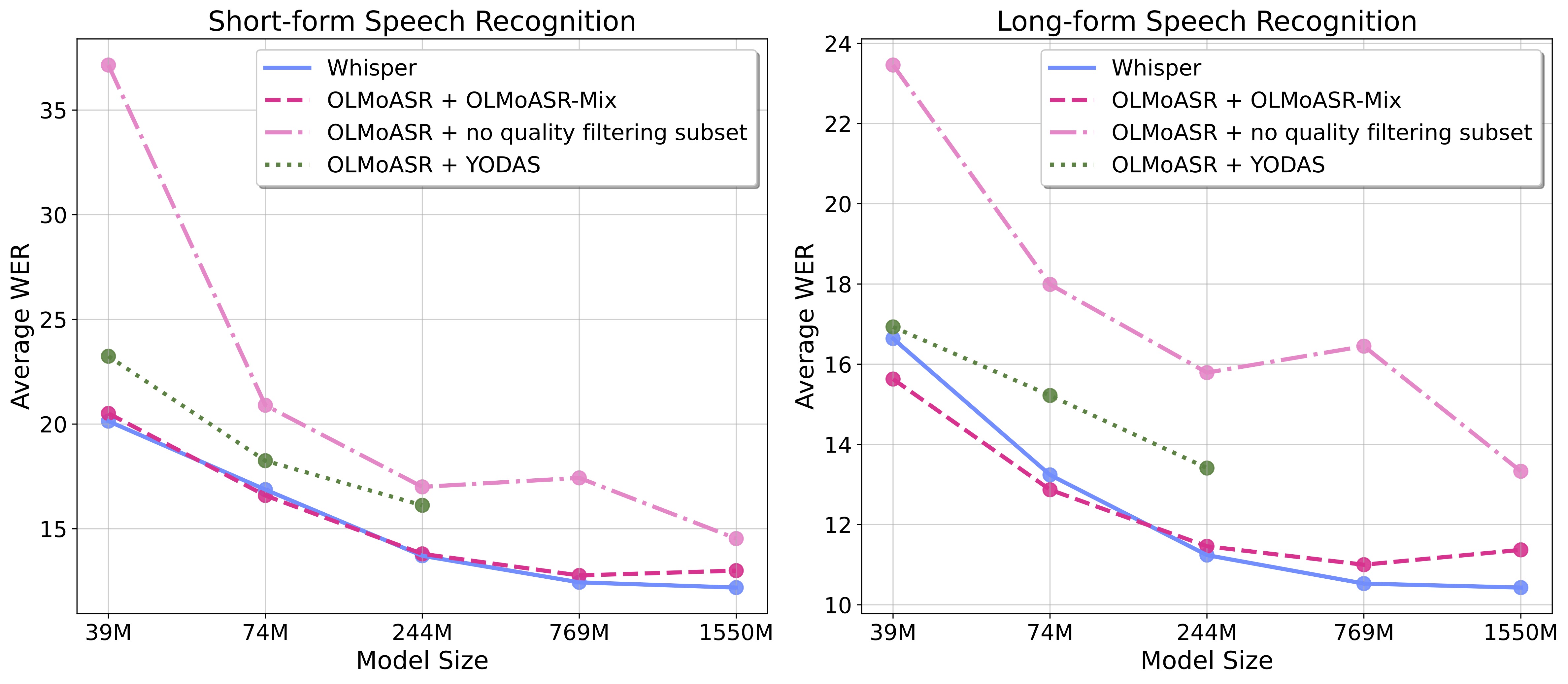
OLMoASR: Open Models and Data for Training Robust Speech Recognition Models.
[GitHub] [Demo] [Models] [Blog]Ngo, H., Deitke, M., Bartelds, M., Pratt, S., Gardner, J., Jordan, M., & Schmidt, L. (2025). OLMoASR: Open Models and Data for Training Robust Speech Recognition Models. arXiv.

BLAB: Brutally Long Audio Bench.
Ahia, O., Bartelds, M., Ahuja, K., Gonen, H., Hofmann, V., Arora, S., Li, S. S., Puttagunta, V., Adeyemi, M., Buchireddy, C., Walls, B., Bennett, N., Watanabe, S., Smith, N. A., Tsvetkov, Y., & Kumar, S. (2025). BLAB: Brutally Long Audio Bench. arXiv.
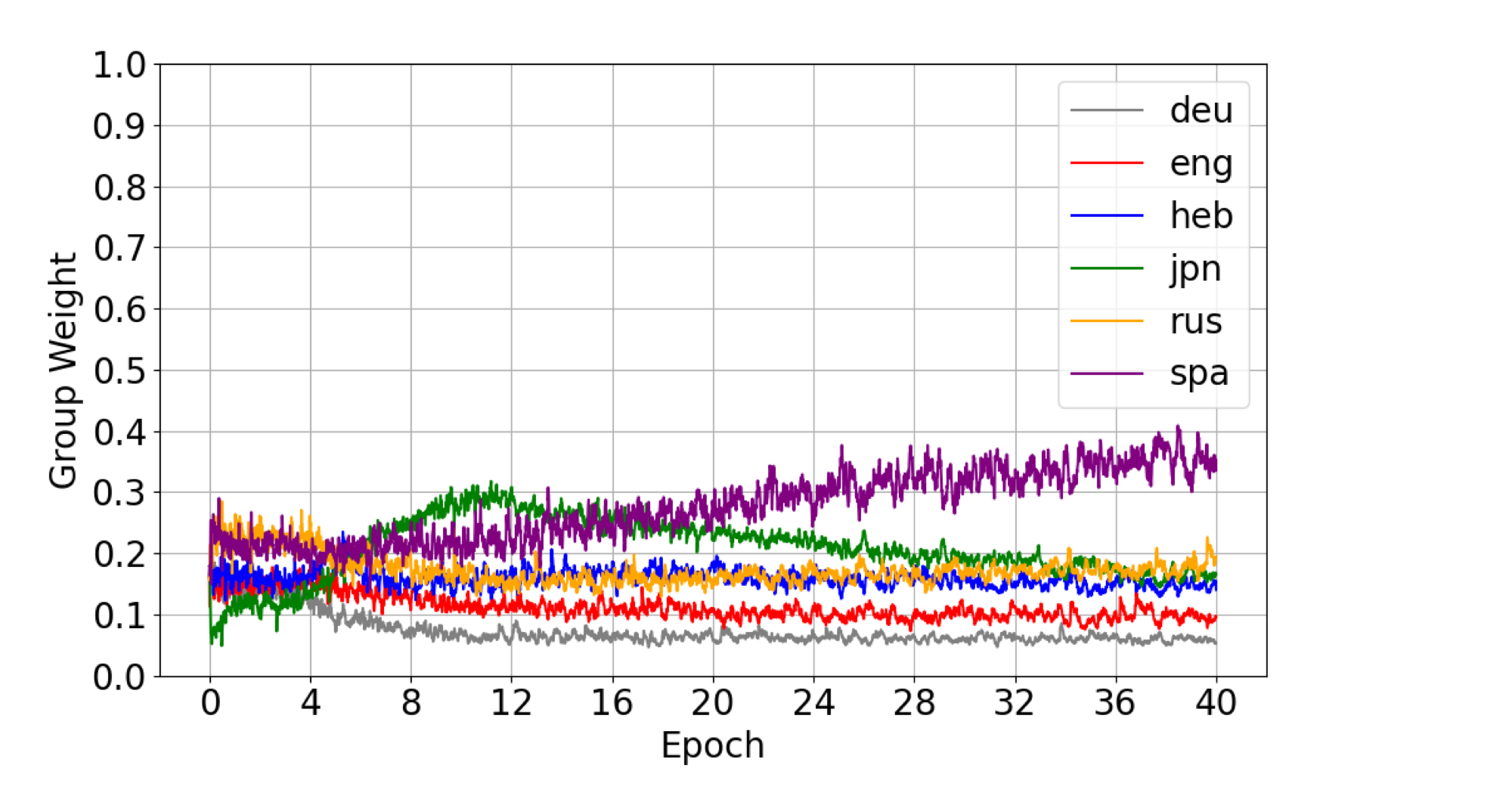
CTC-DRO: Robust Optimization for Reducing Language Disparities in Speech Recognition.
[GitHub] [Video] [Models]*Bartelds, M., *Nandi, A., Doumbouya, M. K. B., Jurafsky, D., Hashimoto, T., & Livescu, K. (2025). CTC-DRO: Robust Optimization for Reducing Language Disparities in Speech Recognition. arXiv.
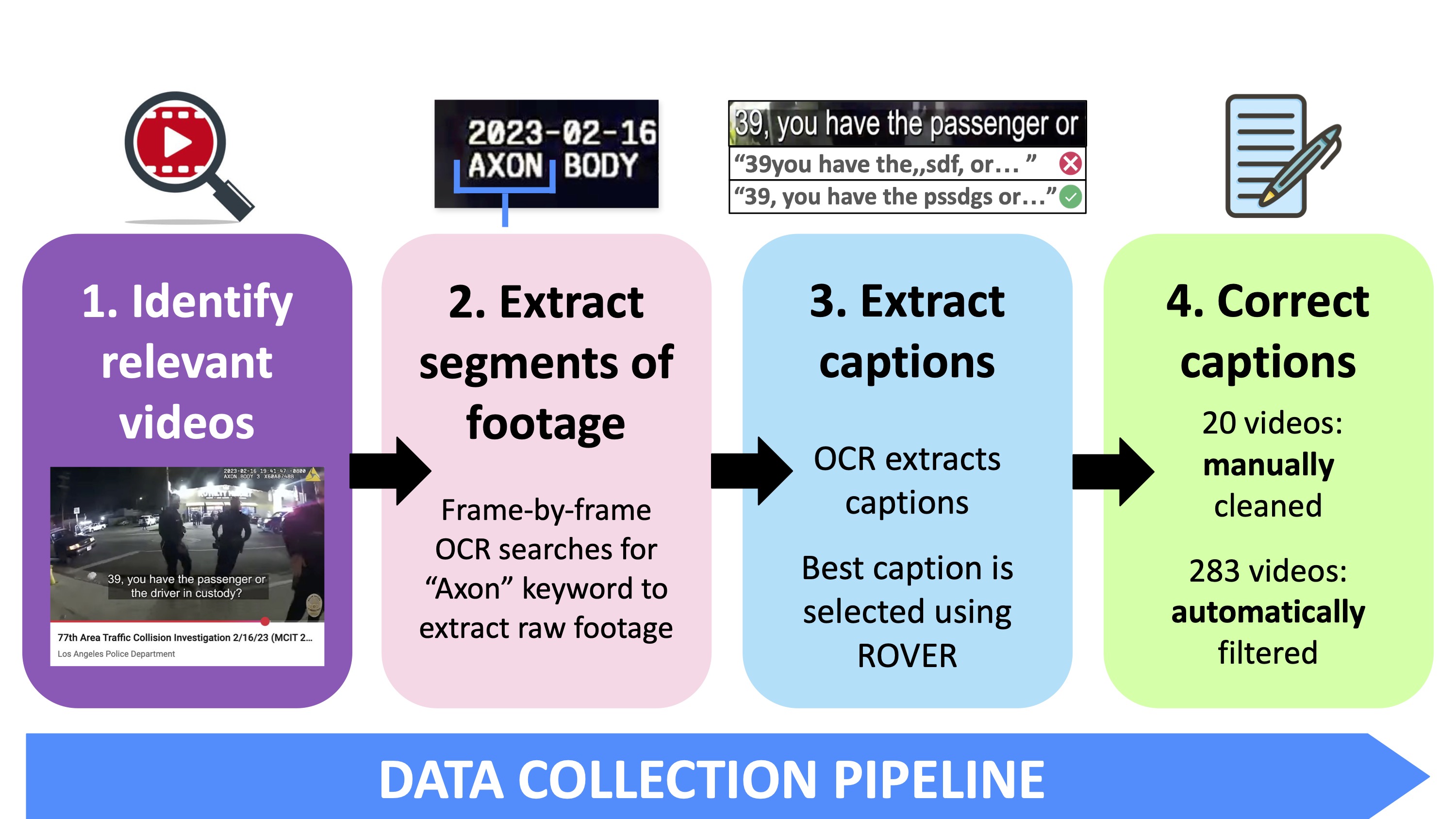
Constructing Datasets From Public Police Body Camera Footage.
Rosas-Smith, J., Bartelds, M., Huang, R., García-Perera, L. P., Livescu, K., Jurafsky, D., & Field, A. (2025). Constructing Datasets From Public Police Body Camera Footage. Proceedings of ICASSP 2025.
ML-SUPERB 2.0: Benchmarking Multilingual Speech Models Across Modeling Constraints, Languages, and Datasets.
[GitHub]Shi, J., *Wang, S.-H., *Chen, W., *Bartelds, M., Kumar, V. B., Tian, J., Chang, X., Jurafsky, D., Livescu, K., Lee, H.-y., & Watanabe, S. (2024). ML-SUPERB 2.0: Benchmarking Multilingual Speech Models Across Modeling Constraints, Languages, and Datasets. Proceedings of Interspeech 2024.
Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation
[GitHub] [Video] [Models]Bartelds, M., San, N., McDonnell, B., Jurafsky, D., & Wieling, M. (2023). Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation. Annual Meeting of the Association for Computational Linguistics (ACL).

Leveraging supplementary text data to kick-start automatic speech recognition system development with limited transcriptions
[GitHub]San, N., Bartelds, M., Billings, B., de Falco, E., Feriza, H., Safri., J., Sahrozi, W., Foley, B., McDonnell, B., & Jurafsky, D. (2023). Leveraging supplementary text data to kick-start automatic speech recognition system development with limited transcriptions. Proceedings of the 6th workshop on the use of Computational Methods in the Study of Endangered Languages (ComputEL-6).

Quantifying Language Variation Acoustically with Few Resources
[GitHub] [Video] [Models]Bartelds, M., & Wieling, M. (2022). Quantifying Language Variation Acoustically with Few Resources. Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL).

Automated speech tools for helping communities process restricted-access corpora for language revival efforts
[GitHub] [Video]San, N., Bartelds, M., Ògúnrẹ̀mí, T., Mount, A., Thompson, R., Higgins, M., Barker, R., Simpson, J., & Jurafsky, D. (2022). Automated speech tools for helping communities process restricted-access corpora for language revival efforts. Proceedings of the 5th workshop on the use of Computational Methods in the Study of Endangered Languages (ComputEL-5).

Neural Representations for Modeling Variation in Speech
[GitHub] [Demo]Bartelds, M., de Vries, W., Sanal, F., Richter, C., Liberman, M., & Wieling, M. (2022). Neural Representations for Modeling Variation in Speech. Journal of Phonetics.

Leveraging Pre-Trained Representations to Improve Access to Untranscribed Speech from Endangered Languages
[GitHub] [Video]*San, N., *Bartelds, M., Browne, M., Clifford, L., Gibson, F., Mansfield, J., ... & Jurafsky, D. (2021). Leveraging Pre-Trained Representations to Improve Access to Untranscribed Speech from Endangered Languages. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU).

Adapting Monolingual Models: Data can be Scarce when Language Similarity is High
[GitHub] [Video]*de Vries, W., *Bartelds, M., Nissim, M., & Wieling, M. (2021). Adapting Monolingual Models: Data can be Scarce when Language Similarity is High. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021.

A New Acoustic-Based Pronunciation Distance Measure
[GitHub]Bartelds, M., Richter, C., Liberman, M., & Wieling, M. (2020). A New Acoustic-Based Pronunciation Distance Measure. Frontiers in Artificial Intelligence, 3, 39.

A novel paradigm to investigate phonetic convergence in interaction
Wieling, M., Tiede, M., Rebernik, T., de Jong, L., Braggaar, A., Bartelds, M., ... & Mills, G. (2020). A novel paradigm to investigate phonetic convergence in interaction. In Proceedings of the 12th International Seminar on Speech Production.

Measuring foreign accent strength using an acoustic distance measure
Bartelds, M., de Vries, W., Richter, C., Liberman, M., & Wieling, M. (2020). Measuring foreign accent strength using an acoustic distance measure. In Proceedings of the 12th International Seminar on Speech Production.
Highlighted Presentations
- Bartelds, M., Nandi, A., Doumbouya, M. K. B., Jurafsky, D., Hashimoto, T., & Livescu, K. (2025). CTC-DRO: Robust Optimization for Reducing Language Disparities in Speech Recognition. Paper presentation at the TTIC Summer Workshop on Foundations of Speech and Audio Foundation Models.
- Bartelds, M. (2025). Improving Universal Access to Modern Speech Technology. Invited talk at Mila.
- Bartelds, M. (2024). ML-SUPERB 2.0: Benchmarking Multilingual Speech Models Across Modeling Constraints, Languages and Datasets. Paper presented at Interspeech 2024.
- Bartelds, M. (2023). Representing Low-Resource Language Varieties: Improved Methods for Spoken Language Processing. Invited talk at the Munich AI & NLP (MaiNLP) research lab at the Center for Information and Language Processing (CIS) at LMU Munich.
- Bartelds, M., San, N., McDonnell, B., Jurafsky, D., & Wieling, M. (2023). Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation. Oral presentation at the 61st Annual Meeting of the Association for Computational Linguistics (ACL).
- Bartelds, M. (2023). What can we do with little data? Speech processing for minority languages, dialects, and accents. Presentation at the Penn Frontotemporal Degeneration Center.
- Bartelds, M., & Wieling, M. (2022). Quantifying Language Variation Acoustically with Few Resources. Poster presentation at the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL).
- *de Vries, W., *Bartelds, M., Nissim, M., & Wieling, M. (2022). Language Similarity in Transfer Learning: the Case of POS Tagging for Gronings and West Frisian. Paper presentation at the Meeting of Computational Linguistics in The Netherlands.
- Bartelds, M. (2022). Building speech and language technologies Dutch language varieties. Invited talk at the BAQONDE project for advancing the use of African languages in education.
- Bartelds, M. (2022). Speech technology for low-resource languages and dialects. Invited talk at the workshop on Low Saxon.
- *San, N., *Bartelds, M., Browne, M., Clifford, L., Gibson, F., Mansfield, J., ... & Jurafsky, D. (2021). Leveraging Pre-Trained Representations to Improve Access to Untranscribed Speech from Endangered Languages. Paper presented at the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU).
- San, N., Bartelds, M., & Jurafsky, D. (2021). Improving Access to Untranscribed Speech by Leveraging Spoken Term Detection and Self-supervised Learning of Speech Representations. Invited non-archival extended abstract presented at SigTyp 2021.
- Bartelds, M. (2021). Van Old noar Jong. Invited talk at the workshop on language diversity in education.
- Bartelds, M., de Vries, W., Richter, C., Liberman, M., & Wieling, M. (2020). Measuring foreign accent strength using an acoustic distance measure. Poster presented at the 12th International Seminar on Speech Production.
- Bartelds, M., & Wieling, M. (2020). Evaluating an Acoustic-based Pronunciation Distance Measure Against Human Perceptual Data. Poster presented at the 30th edition of Computational Linguistics in the Netherlands.
Honors, Awards and Grants
- NWO Rubicon Grant (2023). Breaking barriers: Improving speech recognition for underrepresented languages and dialects. Awarded €145,000.
- Prins Bernhard Cultuurfonds Scholarship (2022). Neural networks for modeling minority languages. Awarded €10,000.
- Co‑applicant CIT Data Science Grant (2020). Dialects of Groningen: from text to speech. Awarded €25,000.
- Co‑applicant Google Community Grant (2019). Van old noar jong: het digitaal doorgeven van Groningse streektaal en identiteit. Awarded €30,000.
Teaching
Stanford University
- Supervised masters student (2025).
- Guest lecturer for the course CS224S (2025).
- Supervised masters student (2024).
- Guest lecturer and project supervisor for the course CS224S (2024).
University of Groningen
- Supervised research intern (2023).
- Supervised research intern (2022).
- Lecturer for the course Introduction to research methods (2022).
- Supervised research intern (2021).
- Supervised four bachelor thesis projects (2021).
- Supervised eight bachelor thesis projects (2020).
- Supervised two research interns (2020).
- Supervised five bachelor thesis projects (2019).
- Supervised research intern (2019).
Other Activities
- Member of the organizing committee of Interspeech 2025 (2025).
- Developed (with Wieling, M.) a questionnaire study to investigate the use and the passing on of Low Saxon dialects within the Lifelines protocol cohort study (30 years longitudinal, data of 167.000 participants). First results are published in Ampersand and Linguistic Minorities in Europe.
- Developed a course (with Wieling, M.) for children in primary schools to introduce them to linguistic research using material from Low Saxon dialects (2021).
- Developed mobile application (with de Vries, W.) for children to make them more acquainted with their local dialect (2021). The mobile application is available in the Play Store and App store.
- Co-organized the 41st TABU Dag, an annual international broad linguistics conference in Groningen, the Netherlands (2021).
- Participated in the 10th Lisbon Machine Learning School (LxMLS 2020).